
목표
- 멀티스레드 환경에서 코루틴을 활용한 성능 최적화 방법
- 고성능 비동기 프로그래밍을 위한 코루틴 조정 전략
- 성능 측정 및 분석을 통한 최적화 실습
일시 중단 함수
일시 중단 함수는 코루틴이 아니다
일시 중단 함수는 코루틴이 아닌, 일시 중단 지점을 포함할 수 있는 코드의 집합이다.
일시 중단 함수는, suspend fun 키워드로 선언된 함수로 함수 내에 일시 중단 지점을 포함할 수 있는 함수입니다. 일시 중단 함수는 일반 함수와 마찬가지로 복잡한 코드들을 구조화하고 재사용할 수 있는 코드의 집합으로 만드는 데 사용됩니다. 일시 중단 함수는 코루틴 내부에서 실행되는 코드의 집합일 뿐, 코루틴이 아닙니다.

- 위 코드를 수행하면, 일시 중단 함수가 순차적으로 호출하여 2초 이상 걸린 것을 확인할 수 있습니다.
- 위 코드에서 코루틴은
runBlocking1개이며, 이 코루틴 내부에서 실행되는delayAndPrintWord()함수는 각각 순차적으로 호출됩니다.
- 위 코드에서 코루틴은
일시 중단 함수가 어떻게 동작하는지 파악하려면, 일시 중단 함수 호출부에 일시 중단 함수 내부 코드를 풀어 쓰면 됩니다.
일반 함수와 마찬가지로, 재사용을 위해 코드를 함수로 추출한 것일 뿐입니다.
만약, 위 예시 코드의 일시 중단 함수를 코루틴처럼 사용하고 싶다면, 일시 중단 함수를 코루틴 빌더로 감싸야 합니다.
앞선 예시 코드의 일시 중단 함수를 코루틴 빌더로 감싸면 아래와 같은 결과를 얻을 수 있습니다.

위 예시의 경우, 걸린 시간이 각각의 일시 중단 함수 호출이 완료되기 전에 출력됩니다. 그 이유는, 일시 중단 함수가 실행되자마자 중단 지점(delay)에 걸려서 스레드 사용 권한을 delay 시간 만큼 양보했기 때문입니다.
만약, 일시 중단 함수가 모두 완료된 이후 걸린 시간을 출력하려면, 아래와 같이 코드를 수정해볼 수 있습니다.

일시 중단 함수의 사용
일시 중단 함수는 일시 중단 지점을 포함할 수 있기 때문에, 일시 중단을 할 수 있는 곳에서만 호출이 가능합니다. 코틀린에서 일시 중단 함수를 호출할 수 있는 영역은 아래와 같습니다.
- 코루틴 내부
- 일시 중단 함수 내부
앞선 예시들을 통해 코루틴 내부(runBlocking)에서 일시 중단 함수 호출하는 것을 확인했습니다. 여기서는 일시 중단 함수 내부에서 일시 중단 함수를 호출해보겠습니다.

- 위 예시를 보면, 걸린 시간이 2초인 것을 확인할 수 있습니다.
- 위 코드에서 코루틴은
runBlocking하나이기 때문에 일시 중단 함수 내의 일시 중단 함수가 하나의 코루틴에서 실행되기 때문에 로직이 순차적으로 호출됩니다.
- 위 코드에서 코루틴은
위 예시의 일시 중단 함수를 아래 예시와 같이 코루틴 빌더로 감싸면, 여러 코루틴에서 실행되어 시간을 단축할 수 있습니다.

왜 일시 중단 함수에서는 launch나 async 같은 코루틴 빌더를 호출할 수 없을까?
앞서서 일시 중단 함수를 코루틴 빌더 내에서 호출하는 것은 보았지만, 일시 중단 함수 내에 코루틴 빌더를 사용한 예제는 없었습니다. 그 이유는 아래 사진처럼 일시 중단 함수는 말그대로 일시 중단 지점을 가질 수 있는 코드 집합이기 때문에 CoroutineScope 객체에 접근할 수 없기 때문입니다.
launch나async는CoroutineScope의 확장 함수이기 때문에,CoroutineScope객체에 접근할 수 있을 때 호출이 가능합니다.

launch나 async 같은 코루틴 빌더 함수를 호출할 수 있도록 일시 중단 함수 내부에서 CoroutineScope 객체에 접근할 수 있는 방법에 대해 알아보도록 하겠습니다.
CoroutineScope 객체에 접근 가능한 일시 중단 함수
coroutineScope

coroutineScope 일시 중단 함수는 일시 중단 함수 내 새로운 CoroutineScope 객체를 생성합니다. 이때, 일시 중단 함수 호출부의 CoroutineScope 객체를 통해 새로운 CoroutineScope를 만들기 때문에 구조화를 깨지 않고 객체를 생성할 수 있습니다.


하지만, 위와 같이 구성을 하게 되면 coroutineScope 내부에서 예외가 발생했을 때 부모 코루틴으로 오류를 전파해 최상단 코루틴까지 취소될 수 있어 주의해야 합니다.

이 경우에는, supervisorScope를 활용해서 예외 전파를 제한하면서, 코루틴 구조화를 깨지 않을 수 있습니다.
supervisorScope
supervisorScope일시 중단 함수를 일시 중단 함수 내에서 사용하면 구조화를 깨지 않는 새로운CoroutineScope객체를 만들 수 있고, 이 CoroutineScope 객체 하위에서 실행되는 코루틴들의 예외 전파도 방지할 수 있습니다.


위 예시를 보면, supervisorScope를 활용해서 자식 코루틴에서 발생한 예외를 부모 코루틴으로 전파하지 않아서, 최상단 코루틴이 정상적으로 끝난 것을 확인할 수 있습니다.
- 참고로,
async에서 예외가 발생할 경우 await 함수 호출 시 예외를 노출하기 때문에,await함수를try~catch로 감싸 예외 발생 시 빈 결과를 반환하게 했습니다.
코루틴의 이해
서브루틴과 코루틴
루틴이란?
특정한 일을 처리하기 위한 일련의 명령을 의미하며, 이러한 일련의 명령을 함수 또는 메소드라고 합니다.

- 서브루틴은 함수의 하위(sub)에서 실행되는 함수를 의미하며, 한 번 호출되면 끝까지 실행됩니다.
- 코루틴은 함께(Co) 사용되는 루틴으로, 서로 간에 스레드 사용을 양보하면서 함께 실행됩니다.
- 코루틴은 서로 간에 협력적으로 동작한다고도 합니다.
코루틴의 스레드 양보
코루틴은 작업 중간에 스레드를 더 이상 사용하지 않게 되면 스레드를 양보합니다. 스레드에 코루틴을 할당하는 역할은 CoroutineDispatcher가 진행하지만, 스레드를 양보하는 주체는 코루틴입니다.
코루틴이 스레드를 양보하려면, 코루틴 내에서 직접 스레드 양보를 위한 메소드를 호출해야 합니다. 만약, 코루틴 내에서 스레드 양보를 위한 메소드가 호출되지 않으면, 코루틴이 실행 완료될 때까지 해당 스레드를 점유합니다.
delay 일시 중단 함수를 통한 스레드 양보
코루틴에서 delay 일시 중단 함수를 호출하면, 사용하던 스레드를 양보하고 설정된 시간 동안 코루틴을 일시 중단합니다.
delay 일시 중단 함수 사용 예시를 통해 알아보겠습니다.

- 위 예시의 경우, 하나의 스레드(Test worker)를 각각의 코루틴이 함께 사용한다는 것을 볼 수 있습니다.
- start 로그를 출력한 뒤 각
launch코루틴은 일시 중단이 되었기 때문에, 스레드 양보를 통해 거의 비슷한 시간에launch코루틴이 모두 호출된 것을 알 수 있습니다.
참고) runBlocking 블록 내 runBlocking log가 먼저 찍힌 이유?
최초에 스레드를 점유하고 있는 코루틴은 runBlocking이며 위 예시에서 runBlocking 코루틴 내에는 일시 중단 함수가 없기 때문에 launch 코루틴은 15번째 줄 호출 시 launch 코루틴이 생성은 되었지만, 실제로 호출은 runBlocking 코루틴이 모두 완료된 뒤에야 실행이 가능해집니다.
join과 await을 통한 스레드 양보
join이나 await 함수가 호출되면 해당 함수를 호출한 코루틴은 스레드를 양보하고 join 또는 await 대상 코루틴 내부 코드가 실행 완료될 때까지 일시 중단합니다. join 예시를 통해 알아보겠습니다.

앞서 보았던 delay 일시 중단 함수 예시와 다르게 join() 일시 중단 함수로 인해 runBlocking 코루틴에 중단 지점이 생겼습니다.
- 33번줄이 출력되기 전에, 32번 줄의
join()을 통해 해당 Job을 가진 launch 코루틴 완료 로그가 찍히는 것을 볼 수 있습니다.
yield 함수를 통한 스레드 양보
앞서 살펴본 delay나 join 같은 일시 중단 함수들은 스레드 양보를 직접 호출하지 않아도 작업 내부적으로 스레드 양보를 발생시킵니다. 간혹 특수한 상황에서는 스레드 양보를 직접 호출해야 할 필요성이 있고, 이를 위해 코루틴에서는 yield 일시 중단 함수를 제공합니다.

예를 들어, 위와 같이 중단 지점이 없는 launch 코루틴이 있다고 가정합니다. 해당 코루틴이 이미 시작되었다면, 부모 코루틴에서 cancel 함수를 날리는 로직을 구현하였더라도, launch 코루틴이 스레드 점유를 해제하지 않아 cancel 함수가 호출이 불가하여 위처럼 무한하게 launch 코루틴을 호출합니다.

이때 위와 같이 일시 중단 지점이 없는 코루틴에 yield 함수를 호출해주면, 스레드를 양보할 수 있어 부모 코루틴이 다시 동작할 수 있어집니다. 이처럼 스레드를 명시적으로 양보해야 할 때 yield 함수를 사용합니다.
코루틴의 실행 스레드는 코루틴이 재개될 때 바뀔 수 있다
코루틴 일시 중단 후 재개되면 CoroutineDispatcher 객체는 재개된 코루틴을 다시 스레드에 할당합니다. CoroutineDispatcher가 코루틴을 스레드에 할당할 때에는, 해당 코루틴이 사용할 수 있는 스레드 풀 중 하나를 할당하는 것이기 때문에 기존에 수행되던 스레드가 아닌 다른 스레드에서 수행될 수 있습니다.
코루틴이 스레드를 양보하지 않아 일시 중단될 일이 없다면, 실행 스레드가 바뀌지 않습니다.
코루틴의 실행 스레드가 바뀔 수 있는 시점은 코루틴이 재개될 때입니다.

코루틴에 다양한 실행 옵션 부여하기
launch와 async를 공부할 때 파라미터로 start 인자로 CoroutineStart 옵션을 전달할 수 있으며, 앞서 배웠던 LAZY 외에도 여러 옵션을 설정할 수 있습니다.
- CoroutineStart.DEFAULT
- CoroutineStart.ATOMIC
- CoroutineStart.UNDISPATCHED
CoroutineStart.DEFAULT
launch나 async를 호출할 때 start 인자를 따로 설정하지 않으면 기본값인 CoroutineStart.DEFAULT가 설정됩니다.
CoroutineStart.DEFAULT를 사용하면, 코루틴 빌더 함수를 호출한 즉시 생성한 코루틴의 실행을CoroutineDispatcher객체에 예약하며, 코루틴 빌더 함수를 호출한 코루틴은 계속해서 실행됩니다.


위 예시를 보면, launch 함수에 start 파라미터를 넘기지 않아 DEFAULT로 설정된 것을 확인할 수 있습니다.
runBlocking을 실행하는 스레드에서launch함수가 호출되면,runBlocking이 가진CoroutineDispatcher에launch코루틴 실행이 예악됩니다.- 이때,
runBlocking로직 내에 일시 중단 지점이 없고runBlocking이 가진CoroutineDispatcher가 가진 스레드풀을runBlocking이 모두 점유하고 있어runBlocking로직이 모두 완료된 이후에야launch코루틴이 실행됩니다.
CoroutineStart.ATOMIC
앞서 CoroutineStart.DEFAULT에서 살펴본 예시에서 launch가 실행되기 전 해당 job을 취소(실행 대기 상태에서의 취소)하면 launch 코루틴은 실행되지 않고 종료됩니다. 만약, 실행 대기 상태의 코루틴이 취소되는 것을 방지하려면, start 인자에 CoroutineStart.ATOMIC을 넣어주면 됩니다.
CoroutineStart.ATOMIC 옵션은 코루틴의 실행 대기 상태에서 취소를 방지하기 위한 옵션입니다.


CoroutineStart.UNDISPATCHED
일반적인 코루틴은 생성 시, CoroutineDispatcher 객체의 작업 대기열에서 대기하다가 할당 가능한 스레드가 생기면 실행됩니다. CoroutineStart.UNDISPATCHED 옵션을 사용하면, CoroutineDispatcher 대기열을 거치지 않고 호출자의 스레드에서 즉시 실행이 가능합니다. 다만, CoroutineStart.UNDISPATCHED 옵션을 건 코루틴이 일시 중단 된 뒤 재개될 때에는 다른 코루틴과 마찬가지로 CoroutineDispatcher 대기열을 거쳐 동작하게 됩니다.

위 예시에서 알 수 있는 점은 아래와 같습니다.
runBlocking의 로그가 찍히기 전launch시작 로그가 찍힘runBlocking내에 일시 중단 지점이 없지만,launch가UNDISPATCHED모드로 실행되어CoroutineDispatcher대기열 거치지 않고, 호출자(runBlocking)의 스레드에서 바로 실행되었기 때문입니다.
launch가 일시 중단 된 뒤 재개될 때에는,CoroutineDispatcher대기열을 통해 컨텍스트에 맞는 스레드에서 호출됨UNDISPATCHED모드 사용 시 코루틴 재개 시에는CoroutineDispatcher대기열을 거쳐 동작하기 때문입니다.
무제한 디스패처
무제한 디스패처란 코루틴을 자신을 실행시킨 스레드에서 즉시 실행하도록 만드는 디스패처입니다. 이때, 어떤 스레드에서 호출되었는지 상관없이 코루틴을 실행시킬 수 있어 무제한 디스패처라고 불립니다.
제한된 디스패처는 코루틴의 실행을 요청받으면 작업 대기열에 적재한 후 해당 디스패처에서 사용할 수 있는 스레드 중 하나로 보내 실행합니다. 무제한 디스패처는 제한된 디스패처와 달리 현재 자신을 실행한 스레드를 즉시 점유하여 실행됩니다.
즉, 무제한 디스패처를 사용해 실행되는 코루틴은 스레드 스위칭 없이 즉시 실행됩니다.

위 예시에서 무제한 디스패처에 대해 알 수 있는 점은 아래와 같습니다.
runBlocking코루틴에서 무제한 디스패처 코루틴을 실행했기 때문에,runBlocking과 동일한 스레드에서 해당 코루틴이 동작함- 무제한 디스패처를 사용하는 코루틴은 현재 자신을 실행한 스레드를 즉시 점유하여 실행됩니다.(스레드 스위칭 X)
- 무제한 디스패처를 사용하는 코루틴은 중단 시점 이후 재개될 때에는 코루틴을 재개하는 스레드에서 실행됨
- 위 예시에서는
delay()가 끝난 후 재개되기 때문에delay를 실행하는DefaultExecutor스레드에서 재개됩니다.
- 위 예시에서는
무제한 디스패처를 사용해 실행되는 코루틴은 자신을 호출한 스레드에서 실행됩니다. 코루틴을 시작할 때에는 어떤 작업에서 실행하는지가 명확하지만, 코루틴 재개 시에는 어떤 스레드가 재개시키는지 예측하기 어렵습니다.
따라서, 일반 적인 상황에서 무제한 디스패처를 사용하면 비동기 작업이 불안정해지며, 테스트 등 특수한 상황에서만 사용하는 것을 권장합니다.
무제한 디스패처와 CoroutineStart.UNDISPATCHED 차이는?
앞서 살펴본 CoroutineStart.UNDISPATCHED와 무제한 디스패처는 처음 코루틴이 실행될 때, 호출자의 스레드에서 실행된다는 점은 동일합니다. 다만, 해당 코루틴에 일시 중단 지점이 존재할 경우 재개하는 방식이 서로 상이합니다.

위 예시를 보면, 무제한 디스패처와 CoroutineStart.UNDISPATCHED의 처음 실행 시의 스레드는 호출자와 동일하지만 일시 중단 이후 재개될 때 스레드는 서로 상이한 것을 확인할 수 있습니다.
- 무제한 디스패처는 재개 시에도, 자신을 호출한 스레드에서 실행되기 때문에
delay를 실행한 스레드(DefaultExecutor)에서 실행 CoroutineStart.UNDISPATCHED는 재개 시에는CoroutineDispatcher대기열에 들어가서 수행되고, 현재 수행 가능한 스레드가RunBlocking과 동일하여 Test worker 스레드(테스트 환경이어서 Test worker이며, 메인 로직에서는 main 스레드)에서 실행
코루틴에서 일시 중단과 재개 일어나는 원리
일반적으로는 코드 순서대로 로직 수행이 진행되지만, 코루틴은 코드를 실행하는 도중 일시 중단하고 다른 작업으로 전환한 후 필요한 시점에 다시 실행을 재개하는 기능을 지원합니다. 코루틴이 일시 중단을 하고 재개하기 위해서는, 기존에 실행되었던 코루틴에 대한 정보가 저장되어 전달되어야 합니다.

코틀린은 코루틴의 실행 정보를 저장하고 전달할 때 CPS(Continuation Passing Style)라는 프로그래밍 방식을 채택하고 있으며, 이어서 실행해야 할 작업을 전달하기 위해 Continuation 객체를 제공합니다.
Continuation 인터페이스 설명에 적힌 내용:
일시 중단 지점 이후에 실행해야 하는 작업을 나타내는 인터페이스로 T 타입의 값을 반환합니다.
Continuation 객체는 코루틴의 일시 중단 시점에 코루틴의 실행 상태를 저장하며, 이후에 실행해야 할 작업에 대한 정보를 포함하고 있습니다. Continuation 객체를 활용하면, 코루틴 재개 시 앞선 코루틴 상태를 복원하여 작업을 이어서 실행할 수 있습니다.
- 지금까지 다룬 코루틴 API는 고수준 API로
Continuation객체를 통한 코루틴 일시 중단과 재개가 사용자에게 노출되지 않았습니다.- 고수준 API는
Continuation객체를 캡슐화하고 있습니다.
- 고수준 API는
Continuation을 통한 일시 중단과 재개
코루틴에서 일시 중단이 일어나면 Continuation 객체에 실행 정보가 저장되고, resume 함수 호출을 통해 재개될 수 있습니다. CancellableContinuation 타입으로 Continuation 객체를 제공하는 suspendCancellableCoroutine 함수 호출을 통해 Continuation의 저장 정보와 재개하는 법에 대해 알아보겠습니다.

위 예시를 보면, 중단할 때 continuation 객체에 중단된 코루틴의 정보가 들어간 것을 확인할 수 있습니다.
runBlocking코루틴은coroutine#3으로,continuation객체에 있는 정보가CoroutineId(3)인 것으로 보아 해당 코루틴 정보가 잘 들어가있음을 확인할 수 있습니다.
참고로, 위 예시에서 resume()을 호출하지 않으면 일시 중단된 코루틴이 재개되지 못하여 runBlocking 코루틴이 종료되지 않아 프로그램이 종료되지 않습니다.
delay는 내부적으로 suspendCancellableCoroutine으로 호출한다

코루틴 실습을 할 때 자주 사용했던 delay 일시 중단 함수 구현체를 보면, suspendCancellableCoroutine을 사용하는 것을 확인할 수 있으며, 설정한 시간 이후에 resume하도록 설정되어 있는 것을 볼 수 있습니다.
일시 중단 이후 결과 값을 받아와야 한다면?
앞서 살펴본 예시에서는 launch와 같이 값을 반환하지 않는 케이스였습니다. async처럼 값을 반환해야 한다면 아래처럼 CancellableCoroutine의 타입 인자를 반환하고자 하는 값의 타입으로 변경하고, resume 시 해당 값을 넘기면 됩니다.

멀티스레드 환경
공유 상태를 사용하는 코루틴
코루틴은 주로 멀티 스레드 환경에서 실행되기 때문에 공유하는 가변 변수를 사용할 때 주의해야 합니다.
스레드 간 데이터를 전달하거나 공유된 자원을 사용하는 경우 가변 변수를 사용해 상태를 공유하고 업데이트해야 합니다. 이 경우, 멀티 스레드 환경이라면 여러 스레드가 가변 변수에 동시에 접근해 값을 변경하면 데이터의 손실이나 불일치가 발생할 수 있습니다.
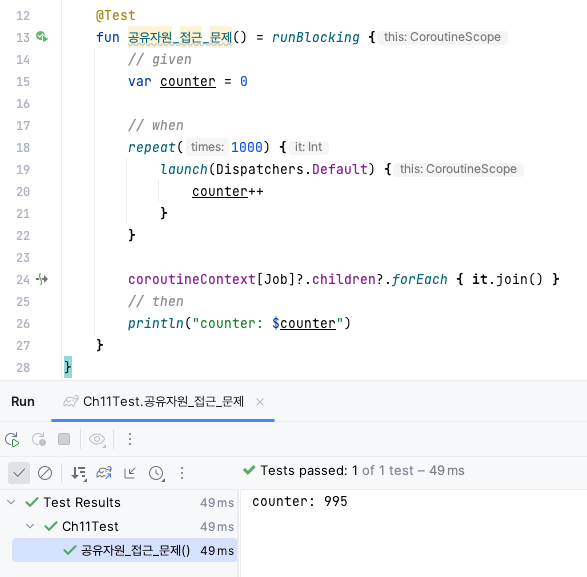
예를 들어 위 코드를 여러번 실행해보면, counter 값은 1000이 아닌 995, 996, 997 등 항상 같은 값이 나오지 않는 것을 확인할 수 있습니다. 같은 코드를 실행해도 다른 결과가 나오는 이유는 아래 이유 때문입니다.
- 메모리 가시성(Memory Visibility) 문제
- 경쟁 상태(Race Condition) 문제
메모리 가시성(Memory Visibility) 문제
The Internal Java Memory Model
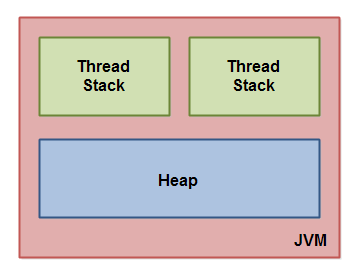
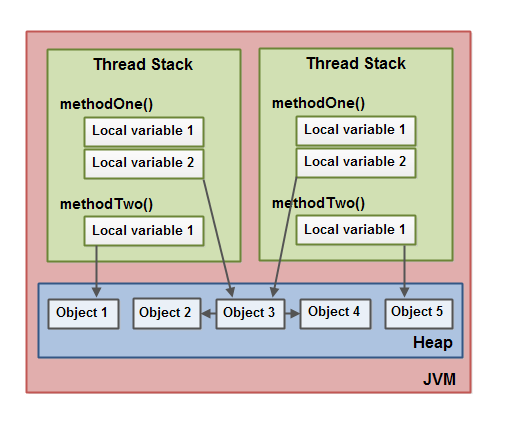
위 사진은 JVM의 thread stack과 heap 메모리 구조를 나타낸 것입니다.
thread stack이 가진 정보
- 스레드가 현재 실행포인트까지 도달할때까지 호출한 메소드들의 정보
- call stack에 있는 모든 메소드가 실행되는데 필요한 모든 로컬 변수
- 원시타입(primitive type -
boolean,byte,short,int,char..)은 thread stack에 완전히 저장됩니다. - 힙 영역에 저장된 객체에 대한 참조(주소 값)도 저장됩니다.
- 원시타입(primitive type -
각각의 스레드는 JVM 상에서 자신만의 thread stack을 가진채로 동작하며, 각 스레드는 자신의 thread stack에만 접근이 가능합니다. 따라서, 특정 스레드에서 생성된 로컬 변수는 동일한 메소드를 호출하는 다른 스레드에서는 볼 수 없습니다.
heap이 가진 정보
- 자바 어플리케이션 실행 중 생성된 모든 객체
heap은 thread stack과 다르게 어플리케이션 내에서 공유합니다. 따라서, A 스레드에서 만든 객체를 B가 접근할 수 있습니다.
Hardware Memory Architecture
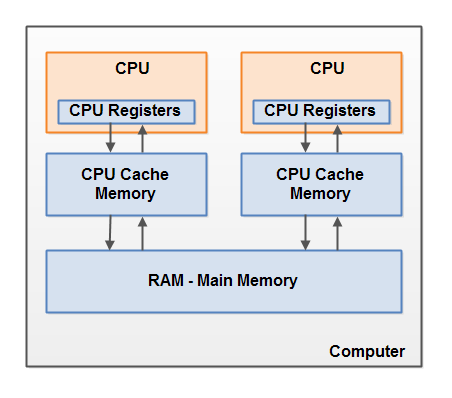
CPU가 2개 이상이면, 컴퓨터는 동시에 여러 스레드를 실행할 수 있습니다(각 CPU는 하나의 스레드를 실행할 수 있음).
메모리 레벨
- Level 1 또는 CPU Register: CPU에 즉시 저장되는 메모리 유형으로 CPU 내부에 존재하여 빠른 접근이 가능해 Main Memory를 통한 데이터 연산보다 훨씬 빠르게 작업이 가능합니다. 가장 일반적으로 사용되는 register는 Accumulator, Program Counter, Address Register 등이 있습니다.
- Level 2 또는 Cache Memory: 빠른 접근을 위해 일시적으로 저장하는 데이터입니다.
- Level 3 또는 Main Memory: 현재 컴퓨터가 가진 메모리로, 작은 사이즈이며 컴퓨터의 전원이 나가면 메모리 내용은 지워집니다.
- Level 4 또는 Secondary Memory: 외부 메모리로, 메인 메모리만큼 빠르지 않지만, 영구적으로 데이터가 남아있습니다.
JVM 메모리 구조와 하드웨어 메모리
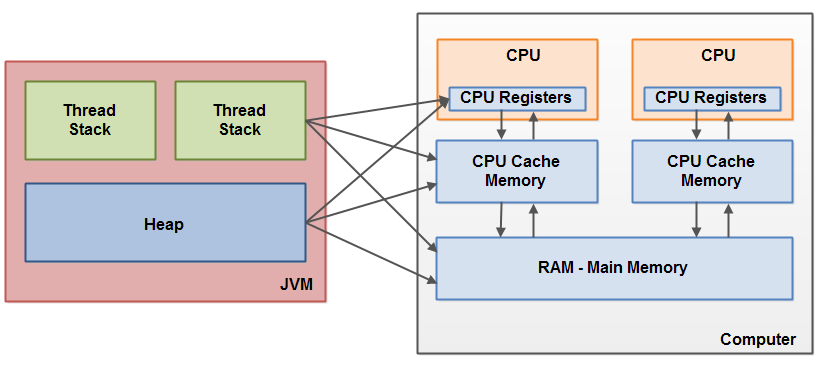
JVM 메모리 구조와 하드웨어 메모리 아키텍처가 상이합니다. 하드웨어 메모리 아키텍처는 thread stack과 heap을 구분하지 않으며, 모두 Main Memory 내 존재합니다. 상황에 따라 thread stack과 heap 메모리 일부는 CPU cache나 CPU Register에 존재할 수도 있습니다.

메모리 가시성 문제란, 스레드가 변수를 읽는 메모리 공간에 관한 문제로 CPU 캐시와 메인 메모리 등으로 이루어진 하드웨어 구조와 연관된 문제입니다. 스레드가 변수를 변경할 때 메인 메모리가 아닌 CPU 캐시를 사용하게 되면 변경된 CPU 캐시 값이 메인 메모리까지 업데이트하는데 시간이 소요되어 CPU 캐시와 메인 메모리 간 데이터 불일치가 발생할 수 있습니다.
공유 상태에 대한 메모리 가시성 문제 해결하기
공유 상태에 대한 메모리 가시성 문제를 해결하려면, @Volatile을 사용할 수 있습니다.

@Volatile 어노테이션이 설정된 변수를 읽고 쓸 때는 CPU 캐시 메모리를 사용하지 않고, 메인 메모리를 사용하여 메모리 가시성 문제를 해결할 수 있습니다.

하지만, @Volatile을 사용하더라도 위 예시에서 결과가 1000이 나오지 않는 것을 확인할 수 있습니다. 이는, 모든 스레드가 항상 메모리에서 counter값을 읽어오지만 동시에 여러 스레드가 하나의 값에 접근하여 동일한 연산이 여러번 발생할 수 있기 때문입니다.
경쟁 상태(Race Condition) 문제

2개의 스레드가 동시에 값을 읽고 업데이트하면, 같은 연산이 두 번 일어납니다. 예를 들어, 앞선 예시에서 counter 변수에 저장된 값이 10일 때, 2개의 스레드가 동시에 counter 변수를 읽고 업데이트하면 11로 업데이트하는 연산이 2번 일어나게 되는 상황을 의미합니다.
공유 상태에 대한 경쟁 상태 문제 해결하기 - Mutex
동시 접근을 제한하는 간단한 방법은 공유 변수의 변경 가능 시점을 임계 영역(Critical Section)으로 만들어 동시 접근을 제한하는 것입니다. 코루틴에 대한 임계 영역을 만들기 위해 Mutex 객체가 제공되며, lock, unlock 메소드를 호출하여 임계 영역 지정이 가능합니다.
- 이때,
lock을 얻는lock()함수는 일시 중단 함수이며,lock을 해제하는unlock()은 일반 함수입니다.



Mutex의 lock 함수는 일시 중단 함수로 구성되어 있으며, 이미 다른 코루틴에 의해 Mutex 객체에 락이 걸려 있으면, 해당 락이 해제되기 전까지 스레드를 양보하고 일시 중단합니다.


Mutex 객체를 사용하여 락을 획득한 후에는 반드시 락을 해제해야 합니다. 만약 해제하지 않으면, 해당 임계 영역에 다른 스레드가 접근할 수 없습니다. 로직이 간단할 때에는 임계 영역 지정이 편하지만, 로직이 복잡해지면 실수로 락을 해제하지 않는 경우가 생길 수 있습니다.
코루틴에서는 이런 상황을 방지하고자 Mutex 객체를 직접 호출하기 보다는 withLock 일시 중단 함수를 제공합니다. withLock 함수를 사용해 임계 영역을 지정하면 좀 더 안전하게 Mutex 객체를 사용할 수 있습니다.
코루틴에서 Mutex 대신 ReetrantLock 객체를 사용하지 않는 이유?

ReetrantLock 객체를 사용해도 Mutex와 동일하게 임계 영역을 생성하기 때문에, 경쟁 상태 문제 해결은 가능합니다. 하지만, 위 ReetrantLock의 withLock 함수는 일반 함수로 일시 중단 함수가 아닙니다. 따라서, ReetrantLock 객체에 대해 lock을 호출했을 떄 이미 다른 스레드에서 락을 획득했다면, 코루틴은 락이 해제될 때까지 lock을 호출한 스레드를 블로킹하고 기다립니다.
Mutex는 락을 기다려야 할 때, 스레드를 양보할 수 있는 반면ReetrantLock은 락을 기다릴 때 스레드를 블로킹하기 때문에Mutex사용하는 것을 권장합니다.
공유 상태에 대한 경쟁 상태 문제 해결하기 - 전용 스레드 사용하기
스레드 간 공유 상태를 사용해 생기는 문제점은 여러 스레드가 공유 상태에 동시에 접근하여 발생합니다. 따라서, 공유 상태에 접근할 때 특정 하나의 전용 스레드만 사용하도록 강제하면 경쟁 상태 문제를 해결할 수 있습니다.

공유 상태에 대한 경쟁 상태 문제 해결하기 - 원자성 있는 데이터 사용하기
경쟁 상태 문제 해결을 위해 원자성 있는 객체를 사용할 수 있습니다. 원자성 있는 객체는 여러 스레드가 동시에 접근해도 한 번에 하나의 스레드만 접근할 수 있도록 제한되어 있어 공유 상태에 대한 경쟁 상태 문제 해결이 가능합니다.

위 예시처럼, AtomicInteger를 사용하면 원자성 있는 객체를 사용하게 됩니다. 원자성 클래스는 AtomicInteger 외에도 AtomicLong, AtomicBoolean 등이 있습니다. 만약, 복잡한 객체에 대해 원자적인 연산이 필요할 경우에는 AtomicReference 클래스를 사용해 원자성을 부여할 수도 있습니다.
원자성 있는 데이터 사용 주의점
원자성 있는 데이터를 사용할 때에는, 데이터 조회와 업데이트를 하나의 함수로 진행해야 합니다. 원자성 있는 데이터는 한 순간에 하나의 스레드만 접근이 가능한 것이기 때문에 조회와 업데이트 메소드를 분리해 사용하면 조회와 업데이트 사이에 다른 스레드가 작업을 할 수 있기 때문에 온전한 결과를 받지 못할 수 있습니다.
또한, 코루틴이 원자성 있는 객체 접근할 때, 이미 다른 스레드가 해당 객체를 사용중이라면, 스레드를 블로킹하고 기다리게 되기 때문에 블로킹시킬 수 있다는 점을 고려하고 사용해야 합니다.
참고 자료
'PROGRAMMING LANGUAGE > KOTLIN' 카테고리의 다른 글
| [Kotlin Coroutine] 코루틴을 활용한 플로우와 상태 흐름 관리 (0) | 2024.07.13 |
|---|---|
| [Effective Kotlin] 4장 추상화 설계 (0) | 2024.07.09 |
| [Effective Kotlin] 3장 재사용성 (0) | 2024.06.30 |
| [Kotlin Coroutine] kotlinx-coroutines-test를 활용한 coroutine 테스트 (0) | 2024.06.29 |
| [Kotlin Coroutine] 고급 코루틴 구조 및 패턴 이해 (0) | 2024.06.27 |